Contingent: 一个完全动态的构建系统
作者:Brandon Rhodes 和 Daniel Rocco
作者简介
Brandon Rhodes 从 1990 年代末开始使用 Python,17 年来一直维护着面向业余天文学家的 PyEphem 库。他在 Dropbox 工作,为企业客户教授 Python 编程课程,参与过诸如新英格兰野花协会的"Go Botany" Django 网站等项目的咨询工作,并将担任 2016 年和 2017 年 PyCon 会议的主席。Brandon 认为编写良好的代码是一种文学形式,格式优美的代码是一件平面设计作品,而正确的代码是思想最透明的表现形式之一。
Daniel Rocco 热爱 Python、咖啡、手工艺、黑啤酒、对象和系统设计、波旁威士忌、教学、树木和拉丁吉他。他为能够以编写 Python 为生而兴奋不已,总是在寻找机会向社区中的其他人学习,并通过分享知识来做出贡献。他是 PyAtl 关于入门主题、测试、设计和新颖事物的常客演讲者;他喜欢看到人们眼中的惊奇和喜悦之光,当有人分享一个新颖、令人惊讶或美丽的想法时。Daniel 与一位微生物学家和四个有抱负的火箭工程师住在亚特兰大。
引言
构建系统(Build systems)长期以来一直是计算机编程中的标准工具。
标准的 make 构建系统,其作者因此获得了 ACM 软件系统奖,于 1976 年首次开发。它不仅让你声明一个输出文件依赖于一个(或多个)输入文件,还让你递归地进行这种声明。例如,一个程序可能依赖于一个目标文件,该目标文件本身又依赖于相应的源代码:
prog: main.o
cc -o prog main.o
main.o: main.c
cc -c -o main.o main.c如果 make 在下次调用时发现 main.c 源代码文件的修改时间比 main.o 更新,那么它不仅会重新构建 main.o 目标文件,还会重新构建 prog 本身。
构建系统是计算机科学本科生的常见学期项目——不仅因为构建系统几乎在所有软件项目中都被使用,还因为它们的构造涉及有向图的基本数据结构和算法(本章稍后将详细讨论)。
在构建系统几十年的使用和实践背后,人们可能期望它们已经变得完全通用,并准备好应对最苛刻的需求。但实际上,构建工件之间的一种常见交互——动态交叉引用问题——被大多数构建系统处理得如此糟糕,以至于在本章中,我们不仅要重述解决 make 问题的经典解决方案和数据结构,还要将该解决方案大幅扩展到一个要求更高的领域。
这个问题,再次强调,是交叉引用。交叉引用往往在哪里出现?在文本文档、说明文档和印刷书籍中!
问题:构建文档系统
从源代码重新构建格式化文档的系统似乎总是做太多工作,或者做太少工作。
当它们因为一个小的编辑而响应,让你等待无关章节重新解析和重新格式化时,它们做了太多工作。但它们也可能重建得太少,留给你一个不一致的最终产品。
考虑 Sphinx,这个文档构建器被用于官方 Python 语言文档和 Python 社区的许多其他项目。Sphinx 项目的 index.rst 通常会包含一个目录:
Table of Contents
=================
.. toctree::
install.rst
tutorial.rst
api.rst这个章节文件名列表告诉 Sphinx 在构建 index.html 输出文件时包含每个三个命名章节的链接。它还会包含每个章节内任何小节的链接。去掉标记后,从上述标题和 toctree 命令产生的文本可能是:
Table of Contents
• Installation
• Newcomers Tutorial
• Hello, World
• Adding Logging
• API Reference
• Handy Functions
• Obscure Classes如你所见,这个目录是来自四个不同文件的信息混合体。虽然其基本顺序和结构来自 index.rst,但每个章节和小节的实际标题都是从三个章节源文件本身提取的。
如果你后来重新考虑教程的章节标题——毕竟,"newcomer"这个词听起来如此古雅,就像你的用户是刚到达先锋怀俄明州的定居者一样——那么你会编辑 tutorial.rst 的第一行并写一些更好的东西:
-Newcomers Tutorial
+Beginners Tutorial
==================
Welcome to the tutorial!
This text will take you through the basics of...当你准备重新构建时,Sphinx 会做正确的事情!它会重新构建教程章节本身和索引。(将输出管道传输到 cat 使 Sphinx 在单独的行上宣布每个重建的文件,而不是使用裸回车符反复覆盖包含这些进度更新的单行。)
$ make html | cat
writing output... [ 50%] index
writing output... [100%] tutorial因为 Sphinx 选择重新构建两个文档,不仅 tutorial.html 现在在顶部显示其新标题,而且输出的 index.html 将在目录中显示更新的章节标题。Sphinx 重新构建了一切,使输出保持一致。
如果你对 tutorial.rst 的编辑更小呢?
Beginners Tutorial
==================
-Welcome to the tutorial!
+Welcome to our project tutorial!
This text will take you through the basics of...在这种情况下,没有必要重新构建 index.html,因为对段落内部的这种小编辑不会改变目录中的任何信息。但事实证明,Sphinx 并不像一开始看起来那么聪明!即使生成的内容完全相同,它也会继续执行重新构建 index.html 的冗余工作。
writing output... [ 50%] index
writing output... [100%] tutorial你可以在 index.html 的"之前"和"之后"版本上运行 diff 来确认你的小编辑对首页没有影响——但 Sphinx 还是让你等待它被重新构建。
对于易于编译的小文档,你甚至可能不会注意到额外的重建工作。但当你对长篇、复杂或涉及生成图表或动画等多媒体的文档进行频繁的调整和编辑时,对工作流程的延迟可能会变得显著。虽然 Sphinx 至少在努力不在你进行单个更改时重新构建每个章节——例如,它没有重新构建 install.html 或 api.html 来响应你的 tutorial.rst 编辑——但它做的比必要的还要多。
但事实证明,Sphinx 做了更糟糕的事情:它有时做得太少,留给你可能被用户注意到的不一致输出。
要看到它最简单的失败之一,首先在 API 文档的顶部添加一个交叉引用:
API Reference
=============
+Before reading this, try reading our :doc:`tutorial`!
+
The sections below list every function
and every single class and method offered...Sphinx 会谨慎地重新构建这个 API 参考文档以及项目的 index.html 主页,就像它对目录的通常谨慎一样:
writing output... [ 50%] api
writing output... [100%] index在 api.html 输出文件中,你可以确认 Sphinx 已经将教程章节的吸引人的人类可读标题包含在交叉引用的锚标记中:
<p>Before reading this, try reading our
<a class="reference internal" href="tutorial.html">
<em>Beginners Tutorial</em>
</a>!</p>如果你现在对 tutorial.rst 文件顶部的标题进行另一次编辑会怎样?你将使 三个 输出文件失效:
tutorial.html顶部的标题现在过时了,所以该文件需要重新构建。index.html中的目录仍然有旧标题,所以该文档需要重新构建。api.html第一段中嵌入的交叉引用仍然有旧的章节标题,也需要重新构建。
Sphinx 做了什么?
writing output... [ 50%] index
writing output... [100%] tutorial糟糕。
只有两个文件被重新构建,不是三个。Sphinx 未能正确重新构建你的文档。
如果你现在将 HTML 推送到网络上,用户将在 api.html 顶部的交叉引用中看到旧标题,但一旦链接将他们带到 tutorial.html 本身,就会看到不同的标题——新的标题。这可能发生在 Sphinx 支持的许多种交叉引用中:章节标题、小节标题、段落、类、方法和函数。
构建系统和一致性
上面概述的问题并不是 Sphinx 特有的。它不仅困扰着其他文档系统,如 LaTeX,甚至可能困扰那些只是试图用古老的 make 实用程序指导编译步骤的项目,如果它们的资产恰好以有趣的方式交叉引用的话。
由于这个问题古老且普遍,其解决方案同样具有悠久的历史:
rm -r _build/
make html如果你删除所有输出,你就保证了完全重建!一些项目甚至将 rm -r 别名为名为 clean 的目标,这样只需要快速的 make clean 来清空状态。
通过消除每个中间或输出资产的每个副本,大量的 rm -r 能够强制构建从零开始重新开始——没有可能导致陈旧产品的早期状态记忆。
但我们能否开发出更好的方法?
如果你的构建系统是一个持久进程,它注意到每个章节标题、每个小节标题以及从一个文档的源代码传递到另一个文档文本中的每个交叉引用短语会怎样?在单个源文件更改后,它关于是否重建其他文档的决策可能是精确的,而不是仅仅猜测,并且是正确的,而不是让输出处于不一致状态。
结果将是一个类似于旧的静态 make 工具的系统,但它在构建文件时学习了文件之间的依赖关系——随着交叉引用的添加、更新和删除,动态地添加和删除依赖关系。
在接下来的部分中,我们将在 Python 中构建这样一个工具,名为 Contingent。Contingent 在存在动态依赖关系的情况下保证正确性,同时执行最少可能的重建步骤。虽然它可以应用于任何问题领域,但我们将针对上面概述问题的小版本运行它。
链接任务创建图
任何构建系统都需要一种链接输入和输出的方法。例如,我们上面讨论中的三个标记文本,每个都产生一个相应的 HTML 输出文件。表达这些关系最自然的方式是作为一个盒子和箭头的集合——或者用数学术语来说,节点和边——形成一个图(图 4.1)。
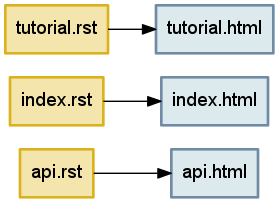
图 4.1 - 通过解析三个输入文本生成的三个文件
程序员在编写构建系统时可能使用的每种语言都会提供各种数据结构,用这些数据结构可以表示这样的节点和边的图。
我们如何在 Python 中表示这样的图?
Python 语言通过在语言语法中直接支持四种通用数据结构来优先考虑它们。你可以通过简单地将它们的字面表示输入到源代码中来创建这些四大数据结构的新实例,它们的四个类型对象作为内置符号提供,无需导入即可使用。
元组是用于保存异构数据的只读序列——元组中的每个槽通常意味着不同的东西。在这里,一个元组将主机名和端口号保持在一起,如果元素重新排序,将失去其意义:
('dropbox.com', 443)列表是用于保存同类数据的可变序列——每个项目通常与其同伴具有相同的结构和含义。列表可以用来保持数据的原始输入顺序,或者可以重新排列或排序以建立新的更有用的顺序。
['C', 'Awk', 'TCL', 'Python', 'JavaScript']集合不保持顺序。集合只记住给定值是否已被添加,而不记住添加了多少次,因此是从数据流中去除重复项的首选数据结构。例如,以下两个集合每个都有三个元素:
{3, 4, 5}
{3, 4, 5, 4, 4, 3, 5, 4, 5, 3, 4, 5}字典是用于存储可通过键访问的值的关联数据结构。字典让程序员选择每个值被索引的键,而不是像元组和列表那样使用自动整数索引。查找由哈希表支持,这意味着字典键查找运行速度相同,无论字典有十几个还是一百万个键。
{'ssh': 22, 'telnet': 23, 'domain': 53, 'http': 80}Python 灵活性的关键在于这四种数据结构是可组合的。程序员可以任意将它们嵌套在彼此内部,以产生更复杂的数据存储,其规则和语法仍然是底层元组、列表、集合和字典的简单规则。
鉴于我们图的每条边都需要知道至少其起源节点和目标节点,最简单的可能表示是一个元组。图 4.1 中的顶部边可能看起来像:
('tutorial.rst', 'tutorial.html')我们如何存储多条边?虽然我们的初始冲动可能是简单地将所有边元组扔到一个列表中,但这会有缺点。列表小心地维护顺序,但谈论图中边的绝对顺序是没有意义的。列表完全乐意持有完全相同边的多个副本,即使我们只希望在 tutorial.rst 和 tutorial.html 之间画一条箭头是可能的。因此正确的选择是集合,它会让我们将图 4.1 表示为:
{('tutorial.rst', 'tutorial.html'),
('index.rst', 'index.html'),
('api.rst', 'api.html')}这将允许快速遍历我们所有的边,单个边的快速插入和删除操作,以及检查特定边是否存在的快速方法。
不幸的是,这些不是我们需要的唯一操作。
像 Contingent 这样的构建系统需要理解给定节点与连接到它的所有节点之间的关系。例如,当 api.rst 更改时,Contingent 需要知道哪些资产(如果有的话)受到该更改的影响,以便在确保完整构建的同时最小化执行的工作。要回答这个问题——"什么节点在 api.rst 的下游?"——我们需要检查来自 api.rst 的传出边。
但构建依赖图也要求 Contingent 关注节点的输入。例如,当构建系统组装输出文档 tutorial.html 时,使用了什么输入?正是通过观察每个节点的输入,Contingent 才能知道 api.html 依赖于 api.rst,但 tutorial.html 不依赖。随着源的更改和重建的发生,Contingent 重建每个更改节点的传入边,以删除可能陈旧的边并重新学习这次任务使用哪些资源。
我们的元组集合不能轻易回答这些问题中的任何一个。如果我们需要知道 api.html 与图的其余部分之间的关系,我们需要遍历整个集合,寻找在 api.html 节点开始或结束的边。
像 Python 的字典这样的关联数据结构会通过允许直接查找特定节点的所有边来使这些任务更容易:
{'tutorial.rst': {('tutorial.rst', 'tutorial.html')},
'tutorial.html': {('tutorial.rst', 'tutorial.html')},
'index.rst': {('index.rst', 'index.html')},
'index.html': {('index.rst', 'index.html')},
'api.rst': {('api.rst', 'api.html')},
'api.html': {('api.rst', 'api.html')}}查找特定节点的边现在会极快,代价是必须存储每条边两次:一次在传入边的集合中,一次在传出边的集合中。但每个集合中的边必须手动检查,以查看哪些是传入的,哪些是传出的。在其边集合中一遍又一遍地保持命名节点也略显冗余。
解决这两个异议的方法是将传入和传出的边放在它们自己独立的数据结构中,这也将免除我们为其涉及的每条边一遍又一遍地提及节点的负担。
incoming = {
'tutorial.html': {'tutorial.rst'},
'index.html': {'index.rst'},
'api.html': {'api.rst'},
}
outgoing = {
'tutorial.rst': {'tutorial.html'},
'index.rst': {'index.html'},
'api.rst': {'api.html'},
}注意 outgoing 直接用 Python 语法表示了我们之前在图 4.1 中绘制的内容:左侧的源文档将被构建系统转换为右侧的输出文档。对于这个简单示例,每个源只指向一个输出——所有输出集合只有一个元素——但我们很快将看到单个输入节点具有多个下游后果的示例。
这个字典集合数据结构中的每条边确实被表示了两次,一次作为从一个节点的传出边(tutorial.rst → tutorial.html),再次作为到另一个节点的传入边(tutorial.html ← tutorial.rst)。这两种表示捕获了完全相同的关系,只是从边两端两个节点的相反角度。但作为这种冗余的回报,数据结构支持 Contingent 需要的快速查找。
类的正确使用
在上面关于 Python 数据结构的讨论中,您可能对类的缺失感到惊讶。毕竟,类是构建应用程序的常见机制,也是其拥护者和反对者之间激烈辩论的主题。类曾经被认为足够重要,以至于整个教育课程都围绕它们设计,大多数流行的编程语言都包含专门的语法来定义和使用它们。
但事实证明,类通常与数据结构设计问题正交。类不是为我们提供完全替代的数据建模范式,而是简单地重复我们已经看到的数据结构:
- 一个类实例被实现为一个字典。
- 一个类实例被使用得像一个可变元组。
类通过更漂亮的语法提供键查找,你可以说 graph.incoming 而不是 graph["incoming"]。但实际上,类实例几乎从不用作通用键值存储。相反,它们用于通过属性名组织相关但异构的数据,实现细节封装在一致且易记的接口之后。
因此,你不是将主机名和端口号放在元组中并必须记住哪个在前哪个在后,而是创建一个 Address 类,其实例每个都有一个 host 和一个 port 属性。然后你可以传递 Address 对象,否则你会有匿名元组。代码变得更容易阅读和编写。但使用类实例实际上并不改变我们上面在进行数据设计时面临的任何问题;它只是提供了一个更漂亮且不那么匿名的容器。
因此,类的真正价值不在于它们改变了数据设计的科学。类的价值在于它们让你隐藏你的数据设计不让程序的其余部分看到!
成功的应用程序设计取决于我们利用 Python 提供的强大内置数据结构的能力,同时最小化我们需要在任何时候保持在头脑中的细节量。类提供了解决这个明显困境的机制:有效使用时,类围绕系统整体设计的某个小子集提供外观。当在一个子集内工作时——例如一个 Graph——我们可以忘记其他子集的实现细节,只要我们能记住它们的接口。这样,程序员在编写系统的过程中经常发现自己在几个抽象级别之间导航,现在使用特定子系统的具体数据模型和实现细节,现在通过它们的接口连接更高级别的概念。
例如,从外部,代码可以简单地要求一个新的 Graph 实例:
>>> from contingent import graphlib
>>> g = graphlib.Graph()而不需要理解 Graph 如何工作的细节。仅使用图的代码在操作图时只看到接口动词——方法调用——如添加边或执行其他操作时:
>>> g.add_edge('index.rst', 'index.html')
>>> g.add_edge('tutorial.rst', 'tutorial.html')
>>> g.add_edge('api.rst', 'api.html')仔细的读者会注意到,我们向图中添加了边而没有显式创建"节点"和"边"对象,并且这些早期示例中的节点本身只是字符串。来自其他语言和传统的人可能期望看到系统中所有内容的用户定义类和接口:
Graph g = new ConcreteGraph();
Node indexRstNode = new StringNode("index.rst");
Node indexHtmlNode = new StringNode("index.html");
Edge indexEdge = new DirectedEdge(indexRstNode, indexHtmlNode);
g.addEdge(indexEdge);Python 语言和社区明确且有意地强调使用简单、通用的数据结构来解决问题,而不是为我们要解决的问题的每个细微细节创建自定义类。这是"Pythonic"解决方案概念的一个方面:Pythonic 解决方案试图最小化语法开销并利用 Python 强大的内置工具和广泛的标准库。
记住这些考虑,让我们回到 Graph 类,检查其设计和实现,以看到数据结构和类接口之间的相互作用。当构造新的 Graph 实例时,已经使用我们在上一节中概述的逻辑构建了一对字典来存储边:
class Graph:
"""A directed graph of the relationships among build tasks."""
def __init__(self):
self._inputs_of = defaultdict(set)
self._consequences_of = defaultdict(set)属性名 _inputs_of 和 _consequences_of 前面的前导下划线是 Python 社区的常见约定,用于表示属性是私有的。这个约定是社区建议程序员通过空间和时间相互传递消息和警告的一种方式。认识到需要在公共和内部对象属性之间发出差异信号,社区采用了单个前导下划线作为向其他程序员(包括我们未来的自己)简洁且相当一致的指示器,表明该属性最好被视为类的不可见内部机械的一部分。
为什么我们使用 defaultdict 而不是标准字典?当组合字典与其他数据结构时,处理缺失键是一个常见问题。使用普通字典,检索不存在的键会引发 KeyError:
>>> consequences_of = {}
>>> consequences_of['index.rst'].add('index.html')
Traceback (most recent call last):
...
KeyError: 'index.rst'使用普通字典需要在整个代码中进行特殊检查来处理这种特定情况,例如在添加新边时:
# Special case to handle "we have not seen this task yet":
if input_task not in self._consequences_of:
self._consequences_of[input_task] = set()
self._consequences_of[input_task].add(consequence_task)这种需求如此常见,以至于 Python 包含了一个特殊的实用工具 defaultdict,它让你提供一个函数来为缺失的键返回值。当我们询问 Graph 尚未见过的边时,我们将得到一个空的 set 而不是异常:
>>> from collections import defaultdict
>>> consequences_of = defaultdict(set)
>>> consequences_of['api.rst']
set()以这种方式构建我们的实现意味着每个键的首次使用可以看起来与特定键第二次和后续使用相同:
>>> consequences_of['index.rst'].add('index.html')
>>> 'index.html' in consequences_of['index.rst']
True给定这些技术,让我们检查 add_edge 的实现,我们之前用它来构建图 4.1 的图。
def add_edge(self, input_task, consequence_task):
"""Add an edge: `consequence_task` uses the output of `input_task`."""
self._consequences_of[input_task].add(consequence_task)
self._inputs_of[consequence_task].add(input_task)这个方法隐藏了每条新边需要两个而不是一个存储步骤的事实,以便我们在两个方向上都知道它。注意 add_edge() 如何不知道或不关心之前是否见过任何一个节点。因为输入和后果数据结构各自是一个 defaultdict(set),add_edge() 方法对节点的新颖性保持愉快的无知——defaultdict 通过即时创建新的 set 对象来处理差异。如我们上面所见,如果我们没有使用 defaultdict,add_edge() 会长三倍。更重要的是,生成的代码更难理解和推理。这个实现演示了解决问题的 Pythonic 方法:简单、直接和简洁。
调用者也应该得到一个简单的方法来访问每条边,而不必学习如何遍历我们的数据结构:
def edges(self):
"""Return all edges as ``(input_task, consequence_task)`` tuples."""
return [(a, b) for a in self.sorted(self._consequences_of)
for b in self.sorted(self._consequences_of[a])]Graph.sorted() 方法尝试以自然排序顺序(如字母顺序)对节点进行排序,可以为用户提供稳定的输出顺序。
学习连接
我们现在有了一种方法让 Contingent 跟踪任务及其之间的关系。但如果我们更仔细地看图 4.2,我们会发现它实际上有点手工制作和模糊:如何从 api.rst 产生 api.html?我们如何知道 index.html 需要教程的标题?这种依赖关系是如何解决的?
当我们手工构建后果图时,我们对这些想法的直觉认识很有用,但不幸的是计算机不是特别直觉,所以我们需要对我们想要的东西更精确。
在 Contingent 中,构建任务被建模为函数加参数。函数定义特定项目理解如何执行的操作。参数提供具体信息:应该读取哪个源文档,需要哪个博客标题。当它们运行时,这些函数可能依次调用其他任务函数,传递它们需要答案的任何参数。
为了看到这是如何工作的,我们现在将实际实现本章开头描述的文档构建器。为了防止我们在细节的沼泽中徘徊,对于这个说明,我们将使用简化的输入和输出文档格式。我们的输入文档将包含第一行的标题,其余文本形成正文。交叉引用将简单地是用反引号括起来的源文件名,在输出时被相应文档的标题替换。
这是我们示例文档的内容:
>>> index = """
... Table of Contents
... -----------------
... * `tutorial.txt`
... * `api.txt`
... """
>>> tutorial = """
... Beginners Tutorial
... ------------------
... Welcome to the tutorial!
... We hope you enjoy it.
... """
>>> api = """
... API Reference
... -------------
... You might want to read
... the `tutorial.txt` first.
... """我们的 read() 任务将假装从磁盘读取文件。由于我们实际上在变量中定义了源文本,它只需要从文件名转换为相应的文本。
>>> filesystem = {'index.txt': index,
... 'tutorial.txt': tutorial,
... 'api.txt': api}
...
>>> @task
... def read(filename):
... return filesystem[filename]parse() 任务根据我们文档格式的规范解释文件内容的原始文本。我们的格式非常简单:文档的标题出现在第一行,其余内容被视为文档的正文。
>>> @task
... def parse(filename):
... lines = read(filename).strip().splitlines()
... title = lines[0]
... body = '\n'.join(lines[2:])
... return title, body注意 parse() 和 read() 之间的连接点——解析的第一个任务是将它得到的文件名传递给 read(),后者找到并返回该文件的内容。
title_of() 任务,给定源文件名,返回文档的标题:
>>> @task
... def title_of(filename):
... title, body = parse(filename)
... return title最后的任务 render() 将文档的内存表示转换为输出形式。它实际上是 parse() 的逆过程。
>>> import re
>>>
>>> LINK = '<a href="{}">{}</a>'
>>> PAGE = '<h1>{}</h1>\n<p>\n{}\n<p>'
>>>
>>> def make_link(match):
... filename = match.group(1)
... return LINK.format(filename, title_of(filename))
...
>>> @task
... def render(filename):
... title, body = parse(filename)
... body = re.sub(r'`([^`]+)`', make_link, body)
... return PAGE.format(title, body)这种函数式设计可能对来自传统面向对象传统的人来说看起来有点奇怪。在 OO 解决方案中,parse() 会返回某种具有 title_of() 作为方法或属性的 Document 对象。Contingent 对这些不同的设计范式没有偏见,并且同样支持这两种方法。
追踪后果
一旦初始构建运行完成,Contingent 需要监控输入文件的更改。当用户完成新编辑并运行"保存"时,read() 方法及其后果都需要被调用。
这将要求我们以与创建图相反的顺序遍历图。你会回忆起,它是通过为 API 参考调用 render() 来构建的,该调用调用了 parse(),最终调用了 read() 任务。现在我们走相反方向:我们知道 read() 现在将返回新内容,我们需要找出下游有什么后果。
编译后果的过程是递归的,因为每个后果本身可以有依赖于它的进一步任务。我们可以通过对图的重复调用手动执行此递归。
这种递归任务——反复寻找直接后果,只有当我们到达没有进一步后果的任务时才停止——是一个足够基本的图操作,Graph 类直接支持它:
>>> pprint(project._graph.recursive_consequences_of([task]))
[parse('api.txt'),
render('api.txt'),
title_of('api.txt'),
render('index.txt')]实际上,recursive_consequences_of() 试图变得聪明一点。如果特定任务作为其他几个任务的下游后果重复出现,那么它小心地在输出列表中只提及一次,并将其移近末尾,使其只出现在作为其输入的任务之后。这种智能由拓扑排序的经典深度优先实现提供支持,该算法通过隐藏的递归辅助函数在 Python 中编写起来相当容易。
如果在检测到更改时,我们小心地重新运行递归后果中的每个任务,那么 Contingent 将能够避免重建太少。然而,我们的第二个挑战是避免重建太多。我们想要避免每次更改 tutorial.txt 时重建所有三个文档,因为大多数编辑可能不会影响其标题,而只会影响其正文。这如何实现?
解决方案是使图重新计算依赖于缓存。当通过更改的递归后果向前步进时,我们只会调用其输入与上次不同的任务。
这种优化将涉及最终的数据结构。我们将给 Project 一个 _todo 集合,用于记住至少一个输入值已更改的每个任务,因此需要重新执行。因为只有 _todo 中的任务过期,构建过程可以跳过运行任何任务,除非它们出现在那里。
更精确地说,重建步骤必须在 _todo 非空时继续循环。在每次循环中,它应该:
调用
recursive_consequences_of()并传入_todo中列出的每个任务。返回值将不仅是_todo任务本身的列表,还有它们下游的每个任务——换句话说,如果输出这次出现不同,可能需要重新执行的每个任务。对于列表中的每个任务,检查它是否在
_todo中列出。如果没有,那么我们可以跳过运行它,因为我们在其上游重新调用的任务都没有产生需要任务重新计算的新返回值。但对于当我们到达它时确实在
_todo中列出的任何任务,我们需要要求它重新运行并重新计算其返回值。如果任务包装函数检测到此返回值与旧缓存值不匹配,那么其下游任务将在我们在递归后果列表中到达它们之前自动添加到_todo。
到我们到达列表末尾时,每个可能需要重新运行的任务实际上都应该重新运行。但以防万一,我们将检查 _todo 并在它还不为空时再试一次。即使对于快速变化的依赖树,这应该很快稳定下来。
结论
存在一些语言和编程方法,在这些方法下,Contingent 将是一个令人窒息的微小类森林,对问题域中的每个概念都给出冗长的名称。
然而,当在 Python 中编程 Contingent 时,我们跳过了创建十几个可能的类,如 TaskArgument、CachedResult 和 ConsequenceList。我们转而依赖 Python 用通用数据结构解决通用问题的强大传统,导致代码反复使用来自核心数据结构元组、列表、集合和字典的少量想法。
但这不会造成问题吗?
通用数据结构就其本质而言也是匿名的。我们的 project._cache 是一个集合。Graph 内部上游和下游节点的每个集合也是如此。我们是否有危险看到通用的 set 错误消息而不知道是在项目还是图实现中寻找错误?
实际上,我们没有危险!
由于封装的严格纪律——只允许 Graph 代码触摸图的集合,Project 代码触摸项目的集合——如果集合操作在项目的后期阶段返回错误,永远不会有歧义。错误时最内层执行方法的名称必然会直接将我们引导到确切涉及错误的类和集合。不需要为 set 的每个可能应用创建子类,只要我们在数据结构属性前面放置传统的下划线,然后小心不要从类外部的代码触摸它们。
Contingent 展示了外观模式(来自划时代的《设计模式》一书)对于设计良好的 Python 程序是多么关键。Python 程序中并非每个数据结构和数据片段都能成为自己的类。相反,类被谨慎使用,在代码中的概念转折点,大想法——如依赖图的想法——可以被包装成一个外观,隐藏下面简单通用数据结构的细节。
外观外部的代码命名它需要的大概念和它想要执行的操作。在外观内部,程序员操作 Python 编程语言的小而方便的移动部件来实现操作。
注: 这是《500 Lines or Less》一书中关于 Contingent 构建系统的完整中文翻译。Contingent 是一个演示如何构建动态依赖跟踪构建系统的项目,展示了 Python 中数据结构设计和面向对象编程的最佳实践。